
【Cloud Integration Hub】CIHでAPIによるパブリケーションを試してみた

データ事業本部の川中子(かわなご)です。
今回はInformaticaで提供されている Cloud Integration Hub (以降CIHと略します)について見ていきます。
本記事の執筆では、こちらのドキュメントを参考にしてます。
また、CIHの概要については以下を公式紹介ページをご参照下さい。
はじめに
今回はCIHにおいてパブリケーション/サブスクリプションを開発する際の選択肢である、
パブリケーション方法 について見ていきます。

各パブリケーション方法の概要は以下になります。
- データ統合タスクによってデータをパブリッシュ: データ統合タスクを起動してトピックへのデータ転送や、トピックからのデータ取得する方法。1タスクで複数トピックとデータ連携する複合パブリケーション/サブスクリプションを使用する事もできる。
- ファイル取り込みタスクでファイルをパブリッシュ: 事前に設定したSecureAgent上のディレクトリを介してデータを連携できる方法。テーブルへのインサートなどはなく、ファイルそのものをファイル取り込みタスクで移動させる。
- APIを使用してデータをパブリッシュ: 発行されるURLへのPOSTをトリガにして起動する方法。テーブルへ格納するデータをbodyに入れてPOSTすることでパブリッシュができる。
今回は上記のうち、APIを利用した方法について見ていきます。
他2つの方法については以下の記事でそれぞれ解説されています。
検証
アセットの準備
今回の検証用に作成したアセットの一覧はコチラになります。
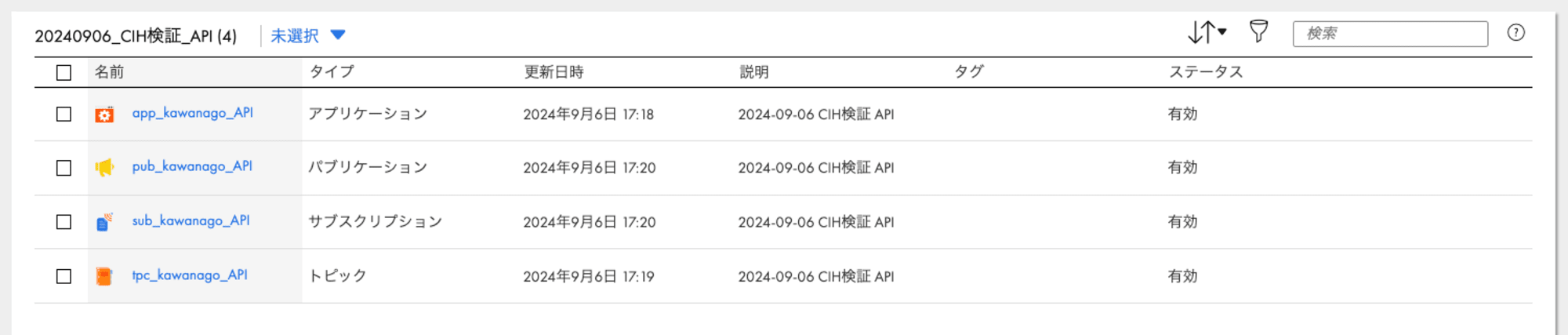
CIHアセット
今回作成するアセットは以下の4つになります。
- アプリケーション
- トピック
- パブリケーション
- サブスクリプション
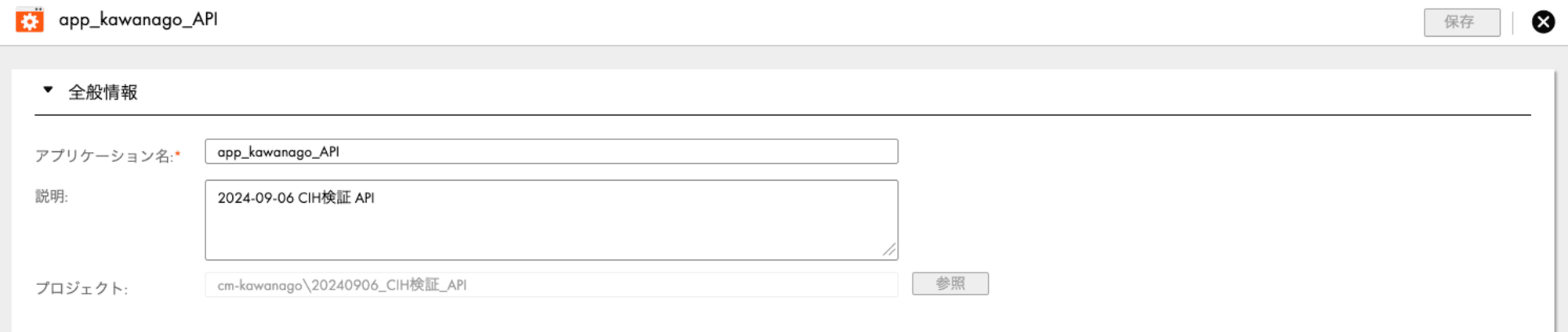
【アプリケーション】
まずはアプリケーションの作成ですが、設定するのはアプリケーション名のみで問題ありません。
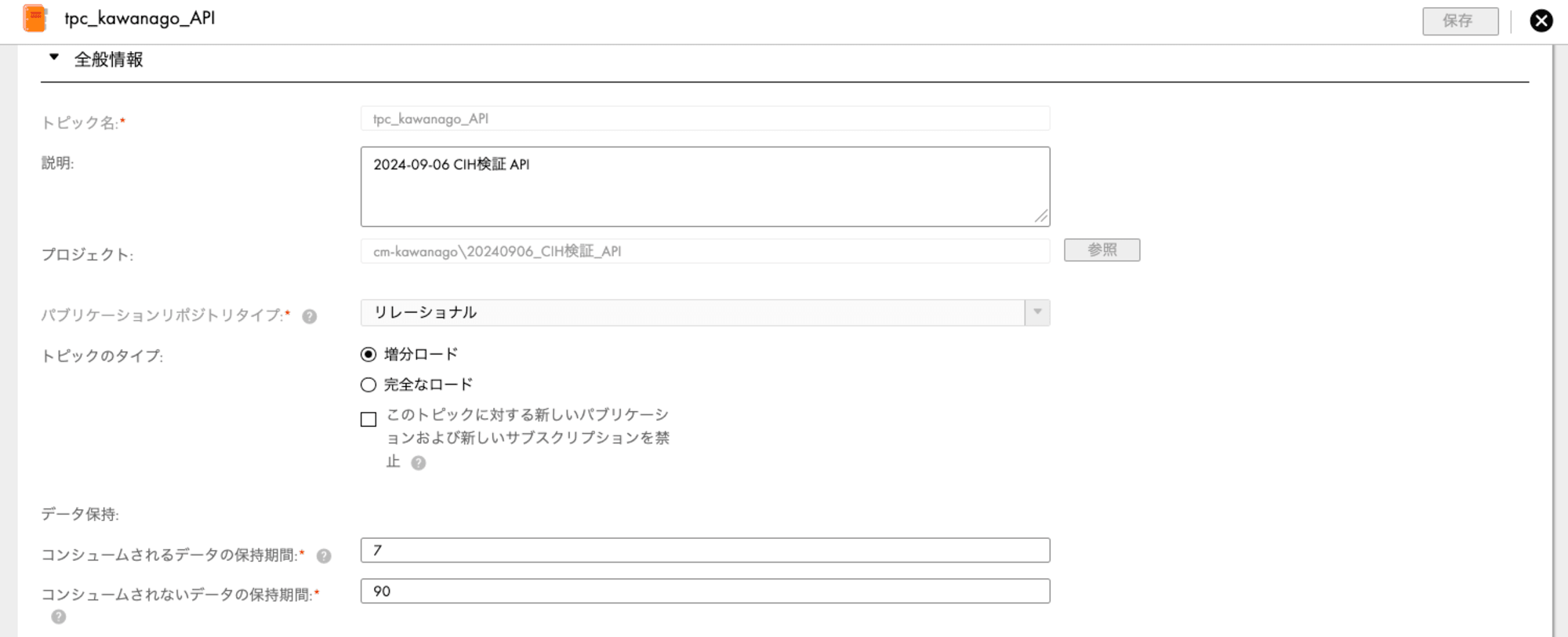
【トピック】
次にトピックを作成します。
パブリケーションリポジトリタイプで「リレーショナル」を設定し、あとは全てデフォルトにしています。
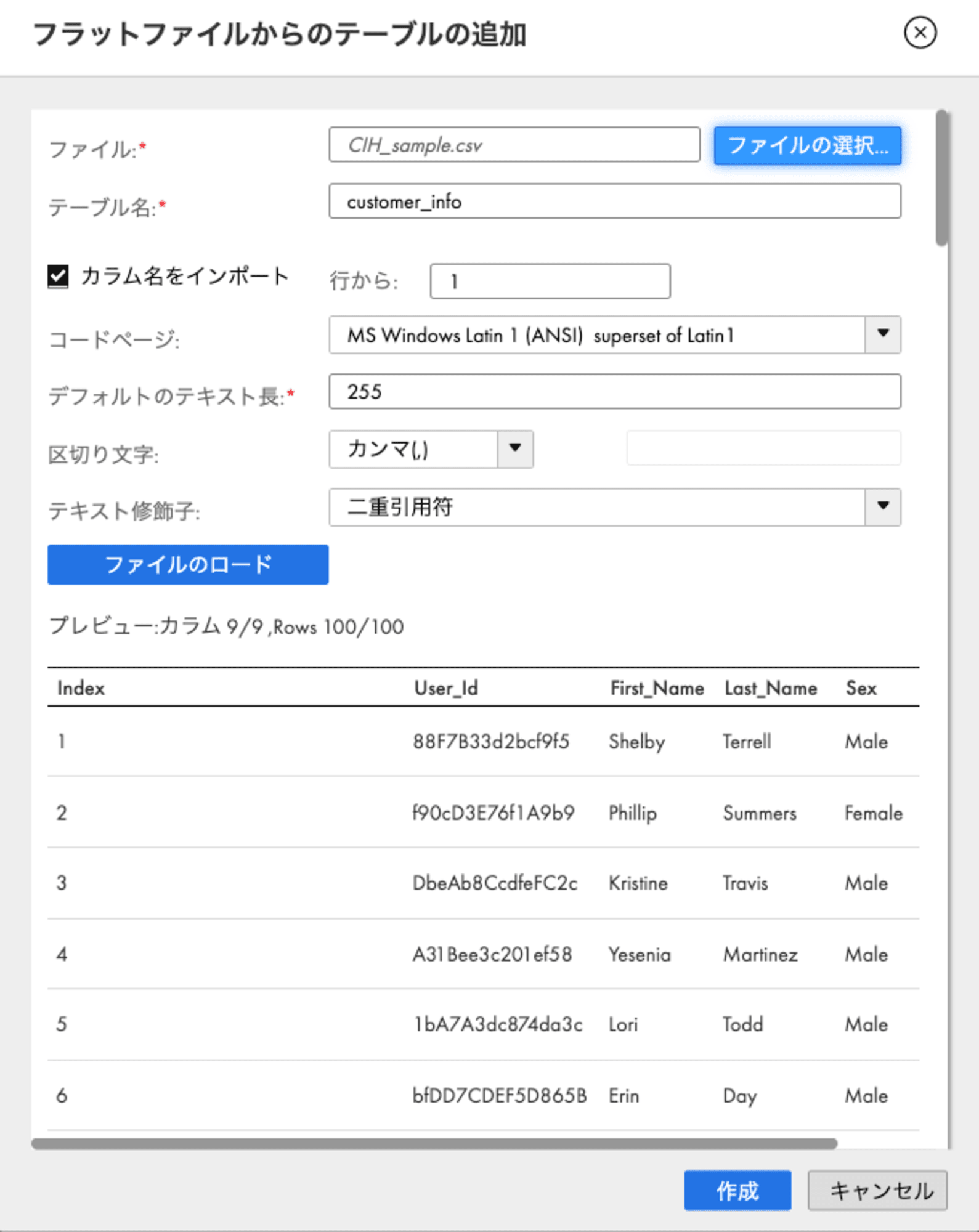
画面下右側の「次からテーブルを作成」を押下し、フラットファイルを選択します。

作成したいテーブルのcsvを選択し、任意のテーブル名を設定します。
また今回はオプションとしてテキスト修飾子を二重引用符にしています。
その後「ファイルのロード」を押下すると、読み込んだテーブルのプレビューが表示されるので、
問題なく読み込まれていることが確認できたら「作成」を押下しましょう。
上記の作業まで完了すると、トピックの設定画面にテーブルの情報が表示されます。
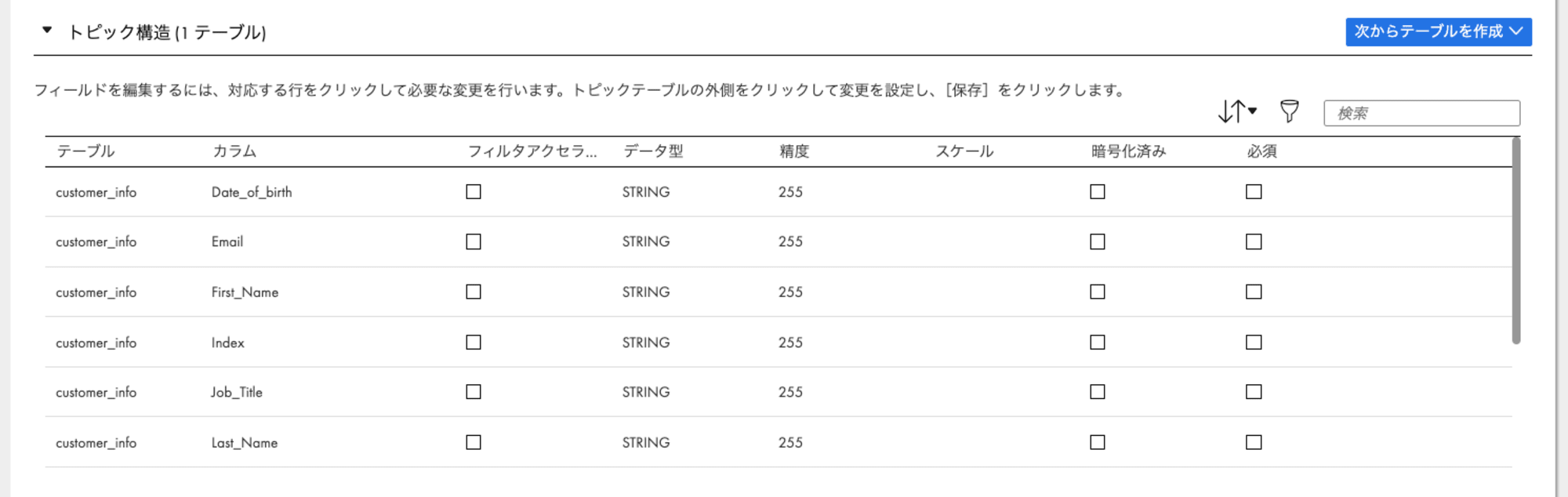
ここで1つ注意点があります。
上記で作成されたテーブルのカラムには"Job_Title"や"First_Name"のように、
アンダースコアで文字列を繋いだ形で表記されているものがいくつか見られます。
しかし今回のテーブル作成に使用したフラットファイル(csv)の中身を見てみると、
カラムは"Job Title"や"First Name"のように、半角スペースを含む形式になっています。
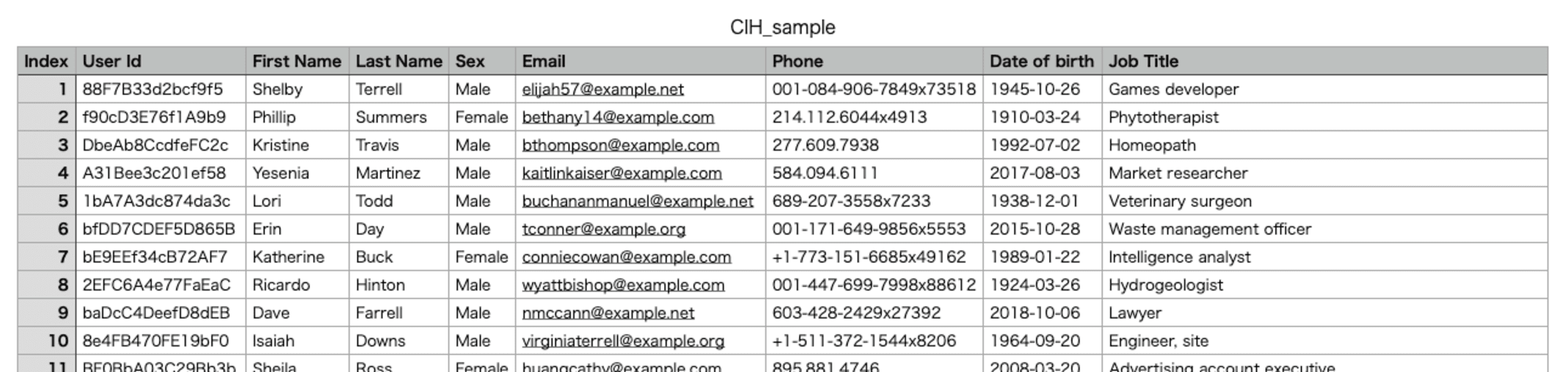
どうやら フラットファイルからの読み込み時に、カラム名にあたる文字列にスペースがあると、
自動的にアンダースコアに変換される処理が行われている ようです。
私は最初これに気が付かず、APIからデータをパブリッシュするときにハマりました。
今回の記事内では、APIからデータを投入する際に少し工夫をしています。
【パブリケーション】
次にパブリケーションを作成します。
パブリケーション方法には「APIを使用してデータをパブリッシュ」を設定します。
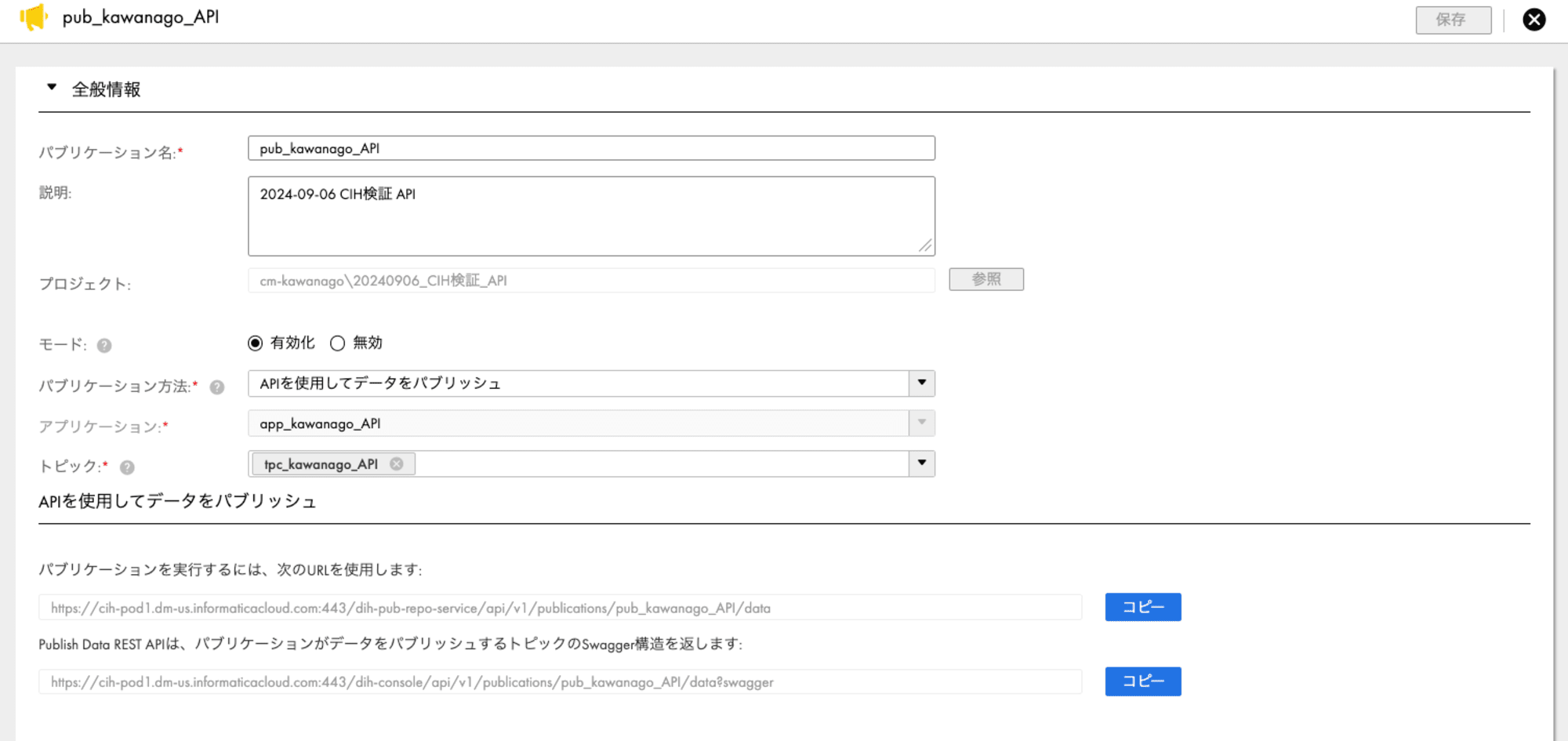
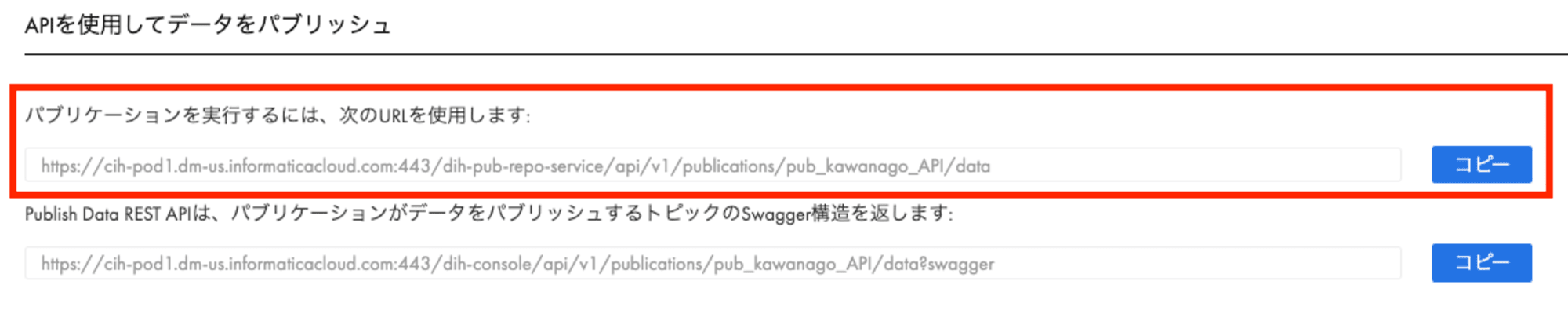
パブリケーション方法を設定すると、画面下部に実行用のURLが表示されます。
このURLは後ほど使用します。
サブスクリプションの設定についても設定方法は同様で、
コンシューム方法に「APIを使用してデータをコンシューム」を選択します。
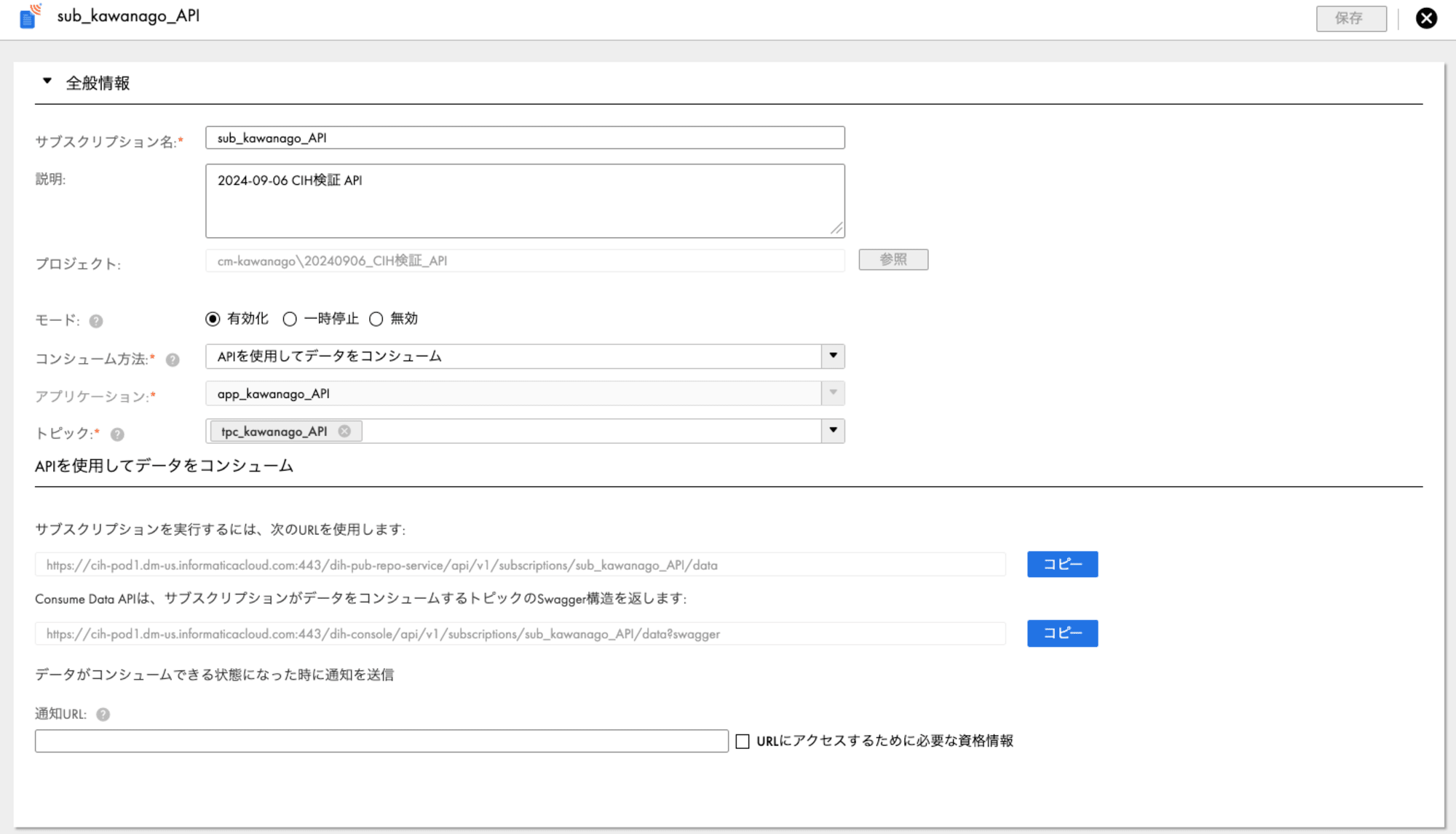
以上でアセットの準備は完了です。
PythonからAPIを実行する
基本設定
アセットが準備できたので、今度はAPIを実行するための準備をしていきます。
今回のデータ連携方法では「Publish Data API」「Consume Data API」と呼ばれるAPIが実行されます。
まずCIHで使用するAPIのヘッダーには共通して、
以下のような形式でベーシック認証の情報が含まれている必要があります。
{
"Username": <[email protected]>,
"Password": <MyPassword>
}
そして今回使用するAPIでは、認証とは別に以下のヘッダー情報が必要です。
{
"Accept": "application/json",
"Content-Type": "application/json"
}
パブリッシュ時、テーブルへ格納したいデータは以下の形式でbodyに含めます。
{
<table_name>:
[
{<column_name_1>: <data_1>, <column_name_2>: <data_2>}
]
}
サブスクリプション側では主に2つの取得方法が指定できます。
イベントIDを直接指定してコンシュームする場合にはpublicationEventIdを使用します。
{
"publicationEventId" : <publicationEventId>
}
それ以外の場合はaggregatedを使用します。
Falseにした場合は最も古いものを、Trueの場合は全てのパブリケーションを取得します。
- true: サブスクリプションは、各API呼び出しで使用可能なすべてのパブリケーションをコンシュームします。
- false: サブスクリプションは、各API呼び出しで最も古いパブリケーションのみをコンシュームします。
{
"aggregated": True
}
通常実行
実際に検証時に渡した1行分のデータはコチラです。
{'Index': '1',
'User_Id': '88F7B33d2bcf9f5',
'First_Name': 'Shelby',
'Last_Name': 'Terrell',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '001-084-906-7849x73518',
'Date_of_birth': '1945-10-26',
'Job_Title': 'Games developer'}
正常にデータのパブリッシュが実行されると、以下のようなレスポンスを受け取ることができます。
{'responseStatus': 'SUCCESS',
'responseExtraMessage': '',
'responseType': '',
'exception': None,
'statsRowsProceeded': 1,
'statsSuccessRows': 1,
'eventId': 460309704}
その後サブスクリプションを実行すると、以下のようなレスポンスを受け取ることができます。
直前にパブリッシュしたデータが受け取れていることが分かります。
{'data': [{'customer_info': [{'Index': '1',
'User_Id': '88F7B33d2bcf9f5',
'First_Name': 'Shelby',
'Last_Name': 'Terrell',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '001-084-906-7849x73518',
'Date_of_birth': '1945-10-26',
'Job_Title': 'Games developer',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-06 05:22:48.000',
'DIH__PUBLICATION_INSTANCE_ID': 460309704}]}],
'responseStatus': 'SUCCESS',
'responseExtraMessage': '',
'responseType': 'application/json',
'aggregatedEventId': '460312087',
'statsSuccessRows': '1',
'statsTotalRows': '1'}
ここまでの状態でCIHのイベントを確認してみると、このようになっています。
パブリケーション側もコンシュームステータスが完了状態になっていることが分かります。
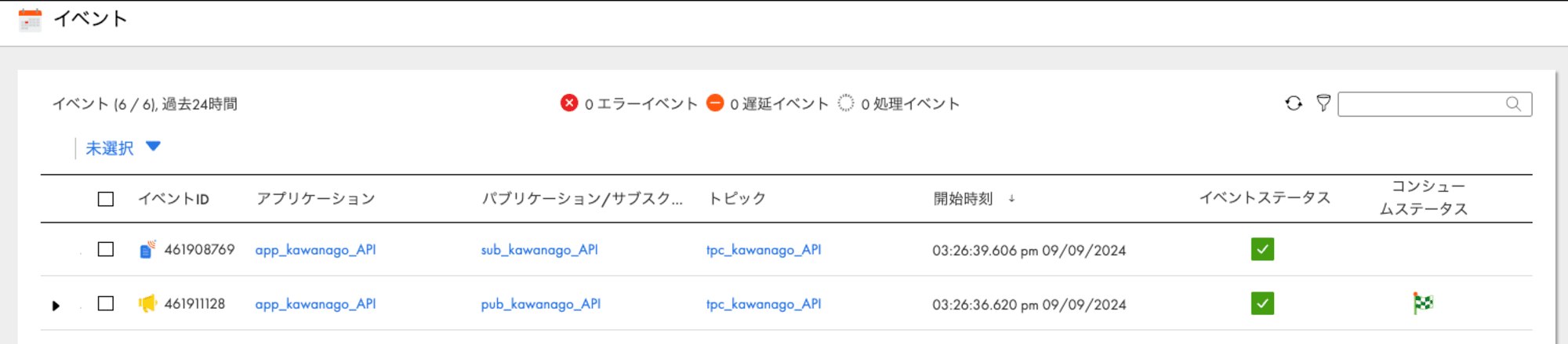
今回は手元で挙動確認だけできればよかったので、ノートブック上で実行しました。
以下に実行した際のコードを一部修正した状態で載せておきます。
APIを実行するためのURLは、CIHのアセット画面からそれぞれコピペして持ってきています。
import json
import requests
import pandas as pd
from requests.auth import HTTPBasicAuth
#==========パラメータ設定(ここは自身の環境に応じて入力して下さい)==========
#CIH画面でコピーしたパブリケーション/サブスクリプション用のURL
url_pub = "https://cih-pod1.dm-us.informaticacloud.com:443/dih-pub-repo-service/api/v1/publications/**********/data"
url_sub = "https://cih-pod1.dm-us.informaticacloud.com:443/dih-pub-repo-service/api/v1/subscriptions/**********/data"
#認証に使用する情報
username = "**********"
password = "**********"
#パブリッシュ先のテーブル名
table_name = "**********"
#==========関数定義==========
#パブリッシュ用の関数
def func_pub(url, table_name, values, username, password):
#ヘッダー
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
#パブリッシュするデータを指定の形で作成
data = {table_name: [values]}
#べーシック認証
auth = HTTPBasicAuth(username, password)
#postを実行して、レスポンスからデータを取り出す
res = requests.post(url, data=json.dumps(data), headers=headers, auth=auth)
try: res = json.loads(res.content.decode())
except: pass
return res
#サブスクリプション用の関数
def func_sub(url, username, password, agg=True):
#ヘッダー
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
#aggregatedをTrueにすると、パブリッシュされた全てのデータを取得できる
data = {"aggregated": agg}
#ベーシック認証
auth = HTTPBasicAuth(username, password)
#postを実行して、レスポンスからデータを取り出す
res = requests.post(url, data=json.dumps(data), headers=headers, auth=auth)
try: res = json.loads(res.content.decode())
except: pass
return res
#==========メイン処理==========
#データ読み込み
df = pd.read_csv("CIH_sample.csv", dtype=str)
#CIHカラム名にスペースがあった場合、"_"で埋められるため処理を合わせておく
df.columns = [c.replace(" ", "_") for c in df.columns]
#パブリッシュするデータを作成(1行分のみ)
values = df.iloc[0, :].to_dict()
#パブリッシュのAPI実行
res_pub = func_pub(url_pub, table_name, values, username, password)
print(res_pub)
#サブスクリプションのAPI実行
res_sub = func_sub(url_sub, username, password)
print(res_sub)
仕様の確認
上記で通常の使用パターンについては確認ができたので、
細かい仕様についていくつか検証をして確認をしていきたいと思います。
【1度のパブリッシュで複数行を扱えるのか】
先ほど実行した形式に沿って、[ ]の中に{column_name: data}を複数並べてみました。
#パブリッシュするデータの形式を拡張して、複数行のデータを送れるか検証
values = []
for i in range(3): values.append(df.iloc[i, :].to_dict())
values
[{'Index': '1',
'User_Id': '88F7B33d2bcf9f5',
'First_Name': 'Shelby',
'Last_Name': 'Terrell',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '001-084-906-7849x73518',
'Date_of_birth': '1945-10-26',
'Job_Title': 'Games developer'},
{'Index': '2',
'User_Id': 'f90cD3E76f1A9b9',
'First_Name': 'Phillip',
'Last_Name': 'Summers',
'Sex': 'Female',
'Email': '[email protected]',
'Phone': '214.112.6044x4913',
'Date_of_birth': '1910-03-24',
'Job_Title': 'Phytotherapist'},
{'Index': '3',
'User_Id': 'DbeAb8CcdfeFC2c',
'First_Name': 'Kristine',
'Last_Name': 'Travis',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '277.609.7938',
'Date_of_birth': '1992-07-02',
'Job_Title': 'Homeopath'}]
実行するとレスポンスとしてSUCCESSのステータスが返ってきました。
{'responseStatus': 'SUCCESS',
'responseExtraMessage': '',
'responseType': '',
'exception': None,
'statsRowsProceeded': 3,
'statsSuccessRows': 3,
'eventId': 461908973}
イベントの画面でも、1つのパブリケーションにまとまっていることが確認できます。

サブスクリプションの方を実行してみると、複数行分のデータが返ってきました。
指定のフォーマットに沿っていれば、複数行のパブリッシュも可能なようです。
{'data': [{'customer_info': [{'Index': '1',
'User_Id': '88F7B33d2bcf9f5',
'First_Name': 'Shelby',
'Last_Name': 'Terrell',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '001-084-906-7849x73518',
'Date_of_birth': '1945-10-26',
'Job_Title': 'Games developer',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-09 06:37:53.000',
'DIH__PUBLICATION_INSTANCE_ID': 461908973},
{'Index': '2',
'User_Id': 'f90cD3E76f1A9b9',
'First_Name': 'Phillip',
'Last_Name': 'Summers',
'Sex': 'Female',
'Email': '[email protected]',
'Phone': '214.112.6044x4913',
'Date_of_birth': '1910-03-24',
'Job_Title': 'Phytotherapist',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-09 06:37:53.000',
'DIH__PUBLICATION_INSTANCE_ID': 461908973},
{'Index': '3',
'User_Id': 'DbeAb8CcdfeFC2c',
'First_Name': 'Kristine',
'Last_Name': 'Travis',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '277.609.7938',
'Date_of_birth': '1992-07-02',
'Job_Title': 'Homeopath',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-09 06:37:53.000',
'DIH__PUBLICATION_INSTANCE_ID': 461908973}]}],
'responseStatus': 'SUCCESS',
'responseExtraMessage': '',
'responseType': 'application/json',
'aggregatedEventId': '461909000',
'statsSuccessRows': '3',
'statsTotalRows': '3'}
【複数行コンシュームの仕様確認】
サブスクリプション側のオプションであるaggregatedの仕様を確認します。
まずは3行分のデータをそれぞれパブリッシュしておきます。
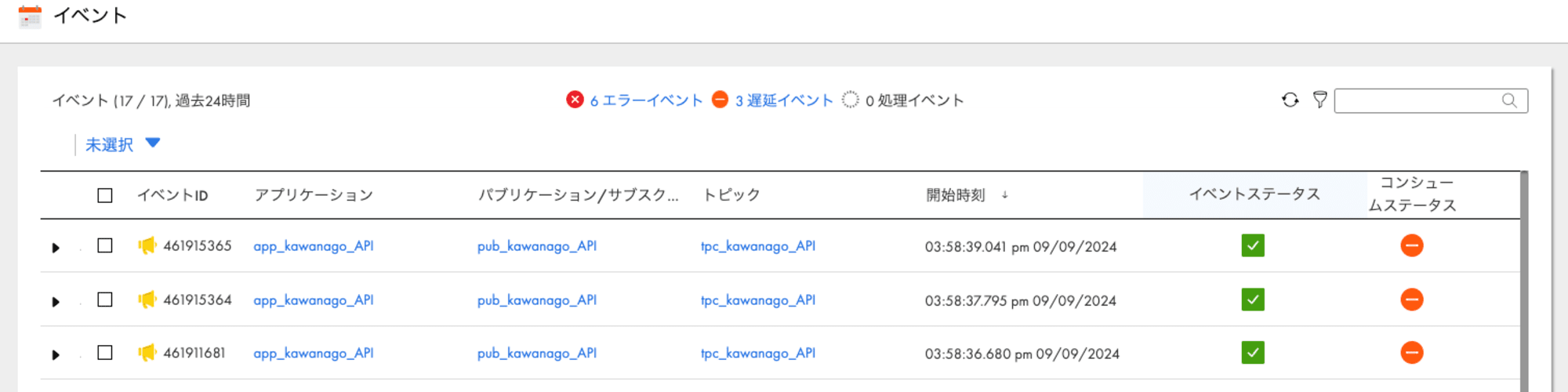
まだサブスクリプションを実行していないので、ステータスは「遅延」になっています。
この状態で、"aggregated": Falseとして実行してみると、1行分だけ取得できました。
{'data': [{'customer_info': [{'Index': '1',
'User_Id': '88F7B33d2bcf9f5',
'First_Name': 'Shelby',
'Last_Name': 'Terrell',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '001-084-906-7849x73518',
'Date_of_birth': '1945-10-26',
'Job_Title': 'Games developer',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-09 06:58:36.000',
'DIH__PUBLICATION_INSTANCE_ID': 461911681}]}],
'responseStatus': 'SUCCESS',
'responseExtraMessage': '',
'responseType': 'application/json',
'aggregatedEventId': '461910803',
'statsSuccessRows': '1',
'statsTotalRows': '1'}
イベントの状態を見ると、一番最初にパブリッシュされた行が完了ステータスになっています。
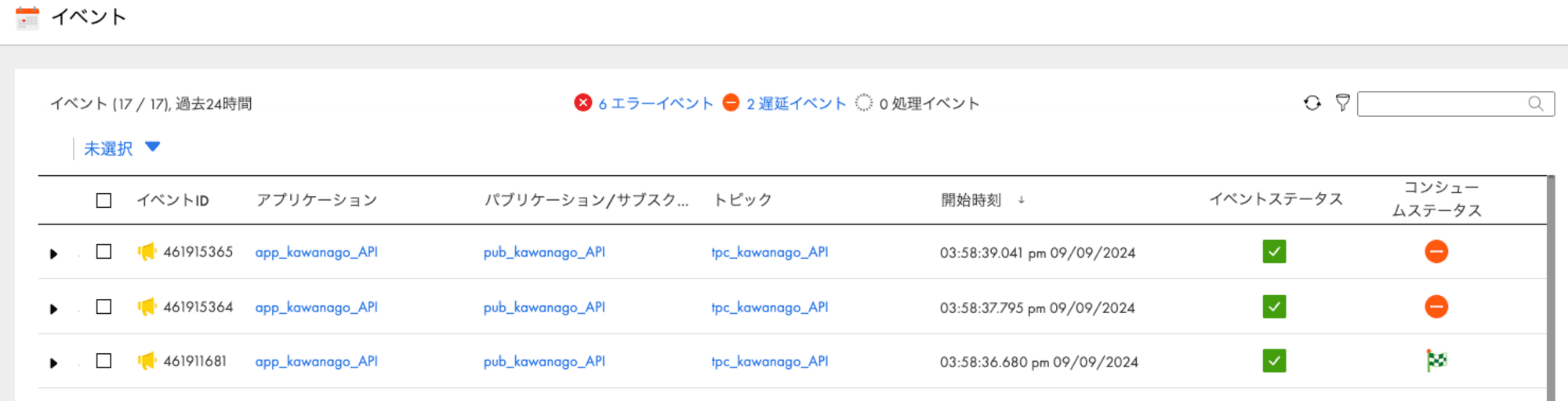
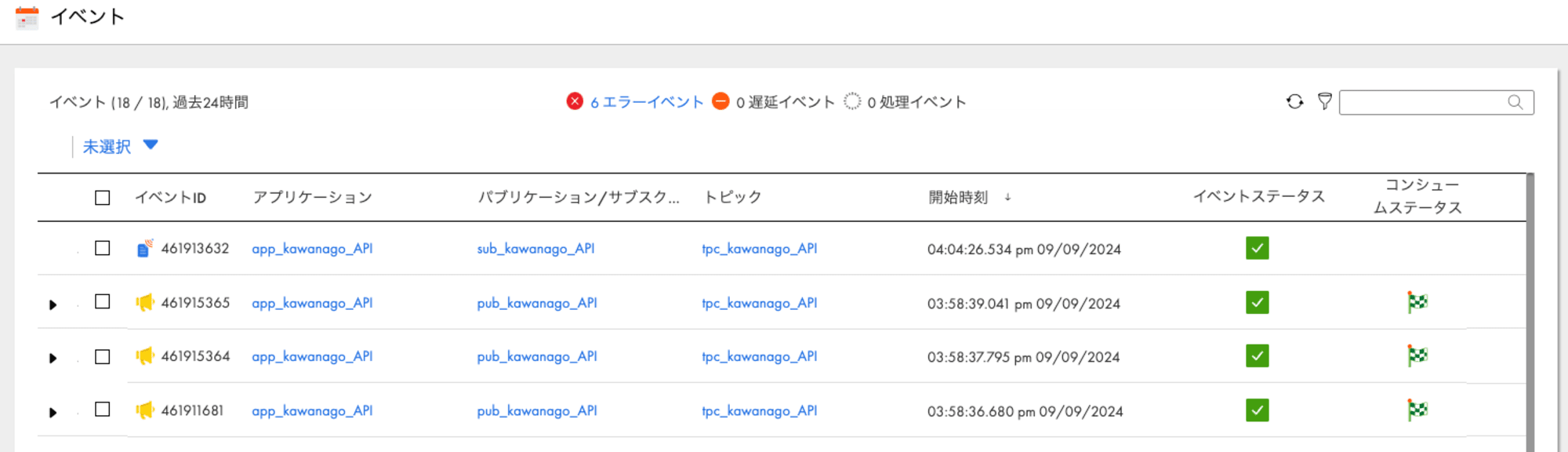
次に"aggregated": Trueとして実行してみると、残りの2行分を取得できました。
{'data': [{'customer_info': [{'Index': '2',
'User_Id': 'f90cD3E76f1A9b9',
'First_Name': 'Phillip',
'Last_Name': 'Summers',
'Sex': 'Female',
'Email': '[email protected]',
'Phone': '214.112.6044x4913',
'Date_of_birth': '1910-03-24',
'Job_Title': 'Phytotherapist',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-09 06:58:37.000',
'DIH__PUBLICATION_INSTANCE_ID': 461915364},
{'Index': '3',
'User_Id': 'DbeAb8CcdfeFC2c',
'First_Name': 'Kristine',
'Last_Name': 'Travis',
'Sex': 'Male',
'Email': '[email protected]',
'Phone': '277.609.7938',
'Date_of_birth': '1992-07-02',
'Job_Title': 'Homeopath',
'DIH__PUBLICATION_INSTANCE_DATE': '2024-09-09 06:58:39.000',
'DIH__PUBLICATION_INSTANCE_ID': 461915365}]}],
'responseStatus': 'SUCCESS',
'responseExtraMessage': '',
'responseType': 'application/json',
'aggregatedEventId': '461913632',
'statsSuccessRows': '2',
'statsTotalRows': '2'}
イベントの方も全てのパブリッシュが完了ステータスになりました。
挙動としてはドキュメントの記載の通りの内容が確認できました。
まとめ
今回はCIHのパブリケーション/サブスクリプションの方法から、
APIによるデータのパブリケーションについて仕様の確認を行いました。
今回は検証対象外でしたが、パブリッシュ完了通知の機能もサブスクリプションには存在します。
こちらを使えば、パブリッシュ→コンシュームの流れもスムーズに自動化ができそうです。

では、以下に今回の検証で分かった内容をまとめてみます。
- トピックで作成したテーブルにAPI経由で直接データをパブリッシュできる
- テーブル作成時、カラム名にスペースがあるとアンダースコアに修正されるので注意
- 指定したフォーマットであれば、複数行分のデータもパブリッシュが可能
- コンシュームのオプションによって取得方法を変更できる
"aggregated": Falseにすると古い方から1つずつコンシュームできる"aggregated": Trueにすると取得可能なものを全てコンシュームできる"aggregated": Trueの場合でも、同時に取得できる上限は2000件
以上、CIH開発や導入検討の参考になれば幸いです。
閲覧頂きありがとうございました。